
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 모두를위한 R데이터분석
- IT
- 도전실전예제
- r
- 초보
- 혼자공부하는C언어
- 혼공C
- c++
- 코딩연습
- 문제해결
- c프로그래밍
- 소수경로
- C언어
- 빅데이터
- c언어문제풀이
- 대학교재풀이
- 빅데이터입문
- 대학교재
- Python
- 알고리즘
- 코딩
- 혼공씨
- 기술
- 코틀린
- 코딩테스트
- 데이터처리
- PrimePath
- Algorithm
- 연습문제
- 모두를위한R데이터분석입문
- Today
- Total
Jupitor's Blog
[코딩테스트] (C++) PrimePath 문제 - Dijkstra 본문
저번 포스트에서 정확한 BFS방법은 아니지만 그와 흡사한 제가 혼자 생각한 알고리즘으로
PrimePath 문제를 풀어보았는데요. 굉장히 느렸고,
Dijkstra 알고리즘이 궁금해서 이 알고리즘으로 한번 해볼까, 싶더군요.
결과를 먼저 말씀드리자면 제가 독자적으로 만들어낸 알고리즘은 Trash(...) 였습니다.
시간이 얼마나 걸렸는지를 먼저 보시죠.


위에가 Dijkstra 알고리즘, 아래가 저의 알고리즘을 이용한 결과입니다.
둘다 최단 경로를 찾아냈지만 시간 차이가 엄청납니다.
Dijkstra는 139ms, 제 건 16252ms... 100배 이상이 차이납니다 =_=;
Dijkstra는 유명한 알고리즘으로 알려져 있고 많은 응용이 된다고 합니다.
자세한 설명은 검색하면 정말 많이 나옵니다.
(wikipedia 짱짱, 사이트 : https://en.wikipedia.org/wiki/Dijkstra%27s_algorithm )
아래는 코드입니다.

isPrime이나 oneDigit은 저번에 사용했던 것과 동일한데
oneDigit의 한 부분이 다릅니다.
Dijkstra 알고리즘을 사용하다가 디버그해보니 자기 자신을 후보군으로 집어넣더군요.
그래서 한자리수가 차이나는지 확인하는 함수에서 차이나는 숫자의 수가 0개일때도 제외시키라고 포함했습니다.

listPrime과 listOneDigit 모두 저번에 사용했던 함수와 동일합니다.
pairOrder는 아래 우선순위 큐를 위해 사용하는데,
second는 노드의 비용을 담을 겁니다. first에는 숫자를 담을거구요.
위와 같이 구조체를 만들고 이를 이용해 priority_queue를 만들면
비용에 따른 min heap이 완성됩니다.

메인 함수입니다.
별로 중요하진 않지만 소수인지 확인하고,
4자리 소수를 모두 포함한 primes 벡터를 생성합니다.
그리고 특정 노드의 이전 노드를 담은 prev와 특정 노드의 비용을 담은 cost를
Unordered_map 으로 선언했는데요.
Dijkstar 알고리즘을 보시면 아시겠지만 어떤 그래프의 모든 꼭짓점에 대해서
시작점에서 그 꼭지점까지 걸리는 비용을 계산, 비교하고 가장 적은 비용을 기록합니다.
그리고 경로를 알기 위해서 해당 노드의 이전 노드를 기억해두는데,
비용을 계산하고 새로 계산한 비용이 이전 비용보다 작을 때 해당 노드의 이전 노드를 변경하게 됩니다.
그리고 Dijkstar 알고리즘에서 이미 탐색한 노드는 지워버리는데,
저는 이를 위해 118번째 줄에 vector의 erase 함수를 이용했습니다.
시작점을 제외한 모든 노드의 비용을 Infinite (여기서는 int의 최댓값을 사용했습니다)으로 설정하고
큐를 사용해서 큐가 빌때까지 실행하는데,
이때 큐는 우선순위 큐입니다. 비용이 가장 작은 경우가 가장 위에 위치해 있는 min priority queue입니다.
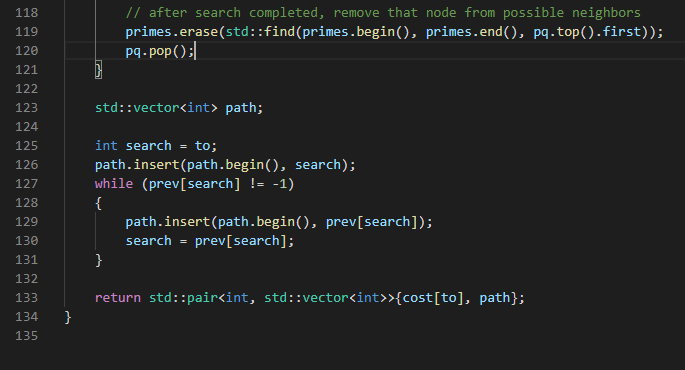
그래서 모든 노드를 탐색하고 나면, 위에 prev와 cost에는
모든 소수에 대한 prime Path의 최소비용과 경로를 알 수 있는 정보가 들어가게 됩니다.
이제 목적지 소수에 담겨있는 이전 노드들을 모두 탐색하고, 목적지 소수에 대한
비용을 담고 있는 cost[to]를 이용하면 끝입니다.
확실히 설명하기가 힘드네요;;
아마 Dijkstra 알고리즘을 조금만 보시면 어떤 부분인지 다 아실겁니다!
'IT > 알고리즘' 카테고리의 다른 글
| [Python] 중위 -> 후위, 전위 수식 변환, 수식 계산, html 태그 체크 (0) | 2021.08.17 |
|---|---|
| [Python] 스택, 큐, 더블큐, 괄호 체크, 10진수 -> 2진수, 10진수 -> n진수 (0) | 2021.08.17 |
| [Python] 시어핀스키와 하노이 (0) | 2021.08.17 |
| nhn 그룹사 신입 개발자 공개채용 프리테스트 1 기출문제 (0) | 2020.09.28 |
| [코딩테스트] PrimePath 문제 (c++) (0) | 2020.08.12 |



